Introduction
Hadoop is supplied by Apache as an open source software framework. It is widely used for the development of data processing applications. These applications are often executed in a distributed computing environment using Apache Hadoop. In today’s class we are going to cover ” Hadoop Architecture and Components“.
In order to achieve high computational power at a very low cost, commodity computers are used in the Hadoop system. The commodity computers are widely available at low prices. The applications which are built using Apache Hadoop are executed on a very large data sets. These data sets are distributed across many clusters of such commodity computers. A computer cluster consists of multiple storage units and processors which collectively acts as a single computing system.
The application data using Hadoop are stored in a distributed file system unlike on a local file system in case of PCs. Such mechanism of data storage using Hadoop is known as Hadoop Distributed File system (HDFS). It uses ‘Data Locality’ concept as a data processing model. In this concept, the computational logic is passed on to cluster nodes i.e. server that contain data. The computational logic is the compiled binaries of the data processing logic program written in a programming language such as Java which executes the logic to process the data stored in Hadoop HDFS (Hadoop Distributed File System).
Hadoop Components
Apache Hadoop mainly contains the following two sub-projects.
- Hadoop MapReduce: In Hadoop, MapReduce is nothing but a computational model as well as a software framework that help to write data processing applications in order to execute them on Hadoop system. Using MapReduce program, we can process huge volume of data in parallel on large clusters of commodity computer’s computation nodes.
- HDFS (Hadoop Distributed File System): Hadoop applications data are stored using HDFS. Data from HDFS is consumed and processed using MapReduce applications. HDFS is capable to create multiple copies of data blocks and allocates them on computation nodes in a cluster. Such data distribution allows consistent and tremendously quick computations as a whole. Therefore, MapReduce along with HDFS together can process a large scale of data very swiftly.
Other known projects at Apache related to Hadoop are HBase (Columnar Data Store), Hive (SQL Interface), Sqoop (Data Exchange), RConnectors (Statistics), Mahout (Machine Learning), Flume (Log Collector), and ZooKeeper (Coordination).
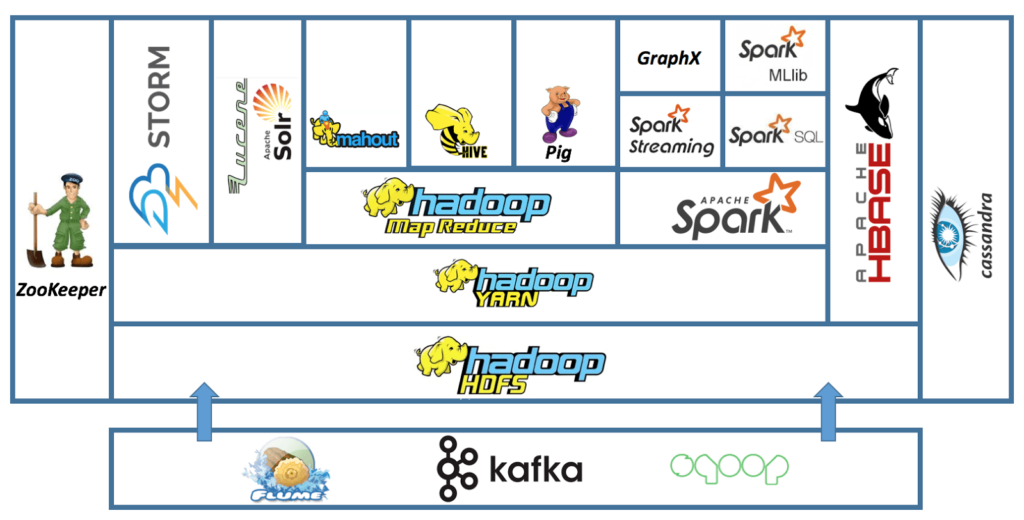
Hadoop Architecture
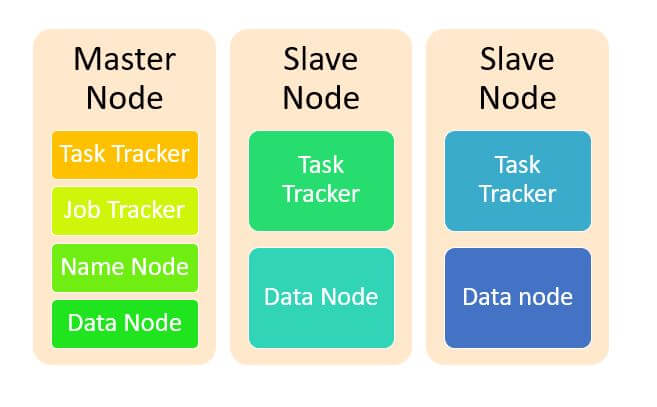
Hadoop obeys a Master and Slave Hadoop Architecture for distributed data storage and processing using the following MapReduce and HDFS methods. The entire master or slave system in Hadoop can be set up in the cloud or physically on premise.
- Master Node: It helps the Hadoop system to conduct parallel processing of date with the use of Hadoop MapReduce.
- Name Node: It represents every file and directory which is present for use in the namespace.
- Data Node: It assist the Hadoop system to manage the state of an HDFS node and helps to interact with the data blocks.
- Slave Node: These nodes are the additional machines which are present in the Hadoop cluster. These machines help to store data for the complex computations. All salve nodes are equipped with a Data Node and Task Tracker which help in the process synchronization with the Name Node and Job tracking respectively.
Characteristics of ‘Hadoop’
Hadoop has the following characteristics.
- Big Data Analysis: Big data storage is distributed in nature which is often unstructured. Therefore, Hadoop is the best suitable mechanism for Big Data Analysis. Data analysis logic written in the Map Reduce can help to extract data from the distributed data storage by occupying very less network bandwidth. Such data extract concept is also known as data locality concept which is always very efficient in Big Data Analysis.
- Scalability: Scaling in HADOOP clusters can be achieved easily by simply adding new cluster nodes in order to allow the growth of Big Data. Such practice does not require the modifications to the actual application logic.
- Fault Tolerance: HADOOP system can easily replicate input data to other cluster nodes and therefore, in the event of any cluster node failure the continuity of business can be sustained easily by forwarding the data analysis request to the other active cluster nodes in the HADOOP System.
Network Topology in HADOOP System
The term topology is the network arrangements of the cluster node in order to synchronize the load distributions. As the size of the Hadoop cluster increases, the network topology may affect the performance of the HADOOP System. It also impacts the system availability and failures. HADOOP system can make use of the network topology for the cluster formation to enhance the performance, availability, and the fault tolerance. Also, network bandwidth is another important factor for the system performance.
In HADOOP system, the network topology is tree and the distance need the tree nodes is known as hops. Hops are considered as important factors on the Hadoop cluster formation. Less the number of hops, more will be the system performance.
Depending on the location of the nodes, the network bandwidth or latency is impacted. If two nodes of a cluster are located at the same data center, then latency will be lower. At the same time, if different nodes of the same cluster are located at the different data centers then latency will be high and hence the performance of the system will be lower in this case.
Conclusion
In this chapter, we discussed about Hadoop components and architecture along with other projects of Hadoop. We also discussed about the various characteristics of Hadoop along with the impact that a network topology can have on the data processing in the Hadoop System.
>>> Checkout Big Data Tutorial List <<<
⇓ Subscribe Us ⇓
If you are not regular reader of this website then highly recommends you to Sign up for our free email newsletter!! Sign up just providing your email address below:
Happy Testing!!!
