


Introduction and Hadoop MapReduce Definitions
Hadoop MapReduce performs a join operation where there is a need to combine two large datasets. It requires lots of code to be written in order to perform the actual join operation. In order to join two large datasets, the size of the two datasets is compared to figure out which dataset is smaller than other datasets. After comparison, the smaller dataset is distributed to every data node in the cluster. Next, the smaller dataset is used by the Reducer or Mapper to perform a lookup operation to find the matching records out of the large dataset. Finally, the matching records from smaller as well as large datasets are combined to form the output joined records.
Types of Join Operations
Join operations in Hadoop MapReduce can be classified into two types. They are Map-side Join and Reduce-side Join.
- Map-side Join Operation: As the name suggests, in this case, the join is performed by the mapper. Here, the join is performed before the data could be consumed by the actual map function. This type of Join has the prerequisite that it requires the input given to the map to be in the form of a partition and all such inputs should be in the sorted order. The equal partitions must be sorted by the join key.
- Reduce-side Join Operations: As the name suggests, in this case, the join is performed by the Reducer. Such type of join does not desire to have a dataset in a partitioned or structured form. Actually, the map side joins processing produces join key as well as the associated corresponding tuples from both of the tables. Therefore, all the tuples which have the same key fall into the same reducer, they are joined to form the output records.H

Hadoop MapReduce Example of Join operation
In the given Hadoop MapReduce example java, the Join operations are demonstrated in the following steps.
Step 1: First of all, you need to ensure that Hadoop has installed on your machine. To begin with the actual process, you need to change the user to ‘hduser’ I.e. id used during Hadoop configuration. Later, you can change to the userid used for your Hadoop config.
Step 2: Do the following in order to create a folder with the required permissions.
sudo mkdir HadoopMapReduceJoinExample sudo chmod -R 777 HadoopMapReduceJoinExample
Folder creation
Step 3: Download the MapReduceJoinExample.zip which has the actual code for demonstrating Join in Hadoop MapReduce.
Step4: Follow the following Steps
sudo tar -xvf MapReduceJoinExample.tar.gz cd MapReduceJoinExample/ $HADOOP_HOME/sbin/start-dfs.sh $HADOOP_HOME/sbin/start-yarn.sh
Copy, Unzip, and start HDFS

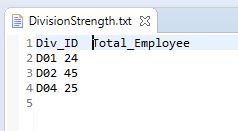

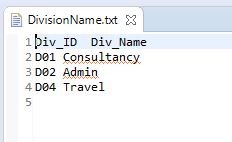
Step 5: The input test files DivisonStrength.txt and DivisonName.txt are the two input files used for this program for Join operation. These files are required to be copied to HDFS using the below command.
$HADOOP_HOME/bin/hdfs dfs –copyFromLocal DivisonStrength.txtDivisonName.txt /
Copy two input files
Step 6: Next, execute the actual program by using the below commands. After execution has completed, the output file (named ‘part-12345’) will be stored in the output directory on HDFS. The results can be viewed from the front end as well as by opening the file ‘part-12345’ present in the output folder.
$HADOOP_HOME/bin/hadoop jar MapReduceJoinExample.jar MapReduceJoinExample/JoinDriver/ DivisonStrength.txt / DivisonName.txt /output $HADOOP_HOME/bin/hdfs dfs -cat /output /part-12345
Copy two input files
MapReduce Counter
MapReduce counter provides mechanisms to collect statistical information about the MapReduce Job. Such information can be used for the diagnosis of any Hadoop MapReduce problems. The counter can be thought of as a similar mechanism; the way log messages are put in the code for a map or reduce. Counters defined in a MapReduce program are incremented during each execution based on a particular event or condition. The counters can be used to calculate or keep a track of valid or invalid records from an input dataset. There are two types of MapReduce Counters as follows.
- Hadoop Built-In counters: Given below are the Hadoop built-in counters. These counters exist per job.
- MapReduce Task Counters: MapReduce task counters are used to collects task-specific information such as a number of input records, etc. at the execution.
- FileSystem Counters: MapReduce files system counters are used to collect information such as the number of bytes read, number of bytes written, etc.
- FileInputFormat Counters: MapReduce FileInputFormat counters are used to collect the information about the number of bytes read through the FileInputFormat.
- FileOutputFormat Counters: MapReduce FileOutputFormat counters are used to collect the information about a number of bytes written through the FileOutputFormat.
- Job Counters: MapReduce Job counters are used by JobTracker to collect Statistics such as the number of tasks launched for a job, etc.
- User-Defined Counters: User-defined counters are not built-in counters but they are the counters defined by the user in order to use them to counter the similar kind of functionalities in their program. E.g., in the Java programming language, ‘enum’ ishttps://www.softwaretestingclass.com/wp-content/uploads/2020/01/MapReduceJoinExample.zip used to describe the user-defined counters.
Example of User Defined Counters is given below MapClassCounter.java
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.Mapper;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reporter;
import org.apache.hadoop.io.Text;
/**
*
* @author Aparajita
*
*/
public class MapClassCounter extends MapReduceBase implements Mapper<LongWritable, Text, Text, Text>
{
static enum OrderCounters { PLACED, PROCESSED };
public void map ( LongWritable key, Text value, OutputCollector<Text, Text> output,
Reporter reporter) throws IOException
{
//Split the Input string by using ',' and stored in 'fields' array
String fields[] = value.toString().split(",", -20);
//5th index value is province. It is stored in 'province' variable
String province = fields[5];
//7th index value is order data. It is stored in 'order' variable
String order = fields[7];
if (province.length() == 0) {
reporter.incrCounter(OrderCounters.PLACED, 1);
} else if (order.startsWith("\"")) {
reporter.incrCounter(OrderCounters.PROCESSED, 1);
} else {
output.collect(new Text(province), new Text(order + ",1"));
}
}
}
Conclusion
In this chapter, we discussed the use of MapReduce Join operations and Counters along with suitable examples.
>>> Checkout Big Data Tutorial List <<<
⇓ Subscribe Us ⇓
If you are not regular reader of this website then highly recommends you to Sign up for our free email newsletter!! Sign up just providing your email address below:
Happy Testing!!!