In earlier class we learned about Tutorial 4: HDFS Read and Write Operation using Java API. Checkout all articles in the Big Data FREE course here:
Big Data Course Syllabus
| Tutorial | Introduction to BigData |
| Tutorial | Introduction to Hadoop Architecture, and Components |
| Tutorial | Hadoop installation on Windows |
| Tutorial | HDFS Read & Write Operation using Java API |
| Tutorial | Hadoop MapReduce |
| Tutorial | Hadoop MapReduce First Program |
| Tutorial | Hadoop MapReduce and Counter |
| Tutorial | Apache Sqoop |
| Tutorial | Apache Flume |
| Tutorial | Hadoop Pig |
| Tutorial | Apache Oozie |
| Tutorial | Big Data Testing |
Introduction
Hadoop MapReduce refers to a programming model which is used to process bulky data. MapReduce program for Hadoop can be written in various programming languages. These languages are Python, Ruby, Java, and C++. Programs for MapReduce can be executed in parallel and therefore, they deliver very high performance in large scale data analysis on multiple commodity computers in the cluster. MapReduce programs execute in two phases viz. Map phase and Reduce phase. Each phase is supplied with key-value pairs as an input and two functions are specified. These two functions are map function and reduce function.

Working of MapReduce
MapReduce process execution can be classified into four phases. These phases are explained below.
- Splitting.
- Mapping.
- Shuffling.
- Reducing.
Let’s understand the execution of MapReduce with the help of an example. Given below is the input data supplied to the Map Reduce Program.
| Input Data to Map Reduce Program |
| Welcome to MapReduce Class MapReduce is useful MapReduce is useless |
Demonstration of MapReduce Architecture
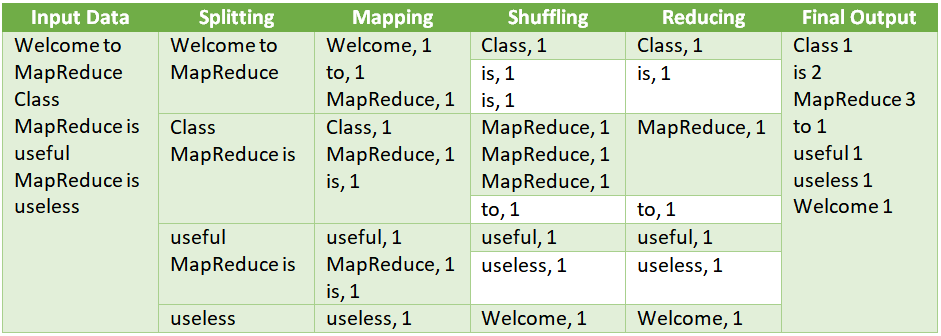
- Splitting: The input data to MapReduce Job gets split into fixed-size pieces called input data splits. Input data split is nothing but a chunk of the input which gets consumed by a single map.
- Mapping: It is the second phase for the MapReduce program. In this phase, the input data splits are supplied to a mapping function in order to produce the output values. In the above example, the job counts the number of occurrences of each word from the input data splits and generates a list of words and their associated frequency.
- Shuffling: In this phase, the output of Mapping phase gets consumed and shuffled to generate a consolidated relevant record. In the above example, the words are clubbed together and sorted in the ascending alphabetic order.
- Reducing: In this phase, the output of shuffling phase gets consumed and aggregated. The output from shuffling phase gets aggregated and generates unique word list along with each word total frequency (i.e. total occurrence of a word) in the input data. It is also known as the summary phase as it generates the complete dataset.
MapReduce Architecture Explanation
MapReduce Architecture is explained below.
- Each input data split has one task associated with it which is executed by the map function.
- Multiple splits have benefits associated with them in terms of time taken by MapReduce Job to execute small split compared to the whole raw input.
- Small splits are fine but too small size splits are not desirable as it will result in the overloading of processing work and management of too many splits will increase the total job execution time.
- Usually the split size should be equal to the size of an HDFS block i.e. 64 MB (by default) for most of the jobs in order to achieve the best results.
- Map tasks after execution trigger the writing of the output to a local disk for the associate node but not to HDFS. This is because to mitigate the replication that takes place in the case of HDFS store operation.
- After Map output has generated, it is further processed by the reduce tasks in order to produce the final output.
- After completion of the job, the map output is discarded and therefore storing it in HDFS with replication becomes overload.
- In case there is a node failure before map output could be consumed by the reduce function, Hadoop will rerun the map task on another available node and re-generates the map output.
- The output of the map task is fed to the reduce task where it is further transferred to the machine which is executing the reduce task.
- The reduce task will merge the output and pass the merged output to the user-defined reduce function.
- Reduce output is stored in HDFS and thus, writing the reduce output.
Work Organization of the MapReduce
Hadoop MapReduce splits the job work into tasks as specified below and explained above with an example.
- Map tasks (Splitting, and Mapping)
- Reduce tasks (Shuffling, and Reducing)
Both Map and Reduce tasks are together controlled by the following two types of entities.
- Jobtracker: It is responsible for the execution of the submitted Job. In other words, it acts like a master. It resides on Namenode and coordinates the action by scheduling tasks to execute on different data nodes.
- Multiple Task Trackers: Each task Job acts as a slave that performs an individual task. The multiple task trackers Jobs reside on Datanode and task tracker is responsible for the completion of the individual task on Data Node. Task tracker sends the progress report to the Job tracker. It intermittently sends ‘heartbeat’ signal to the Jobtracker in order to notify it about the current system state and helps Jobtracker to keep a track of the overall Job progress. In case of any task failure, the Jobtracker is notified and it triggers the re-execution of the failed task on a different task tracker.
Conclusion
In this chapter, we discussed in detail about the functioning of the Hadoop MapReduce programming model along with an example.
>>> Checkout Big Data Tutorial List <<<
⇓ Subscribe Us ⇓
If you are not regular reader of this website then highly recommends you to Sign up for our free email newsletter!! Sign up just providing your email address below:
Happy Testing!!!
