
In this chapter, we are going to discuss Apache Sqoop architecture along with a suitable example. Apache SQOOP stands for SQL to Hadoop and it is based on a connector architecture to support plugins in order to deliver the connectivity to the external database systems. It is capable to support a bulk data transfer (both import and export) from other structured databases such as enterprise data warehouses, relational databases (RDMS), MongoDB (NoSQL system) to HDFS i.e. Hadoop Distributed File System with ease. An enterprise can be an example of SQOOP that imports bulk data for a business day from Relational databases such as Oracle, Sybase, DB2, etc. into the Hive data warehouse for further investigation.
SQOOP Architecture is designed carefully to ensure the connectivity with the external database system along with the dialects of the corresponding databases. Different databases have different dialects and as a result, SQOOP ensures the appropriate dialect reading and writing in order to facilitate smooth data transfer with external database systems and HDFS. All such a data transfer mechanism is possible through Sqoop’s connectors.
Apache SQOOP Connector


Apache SQOOP Connector operates for a wide range of popular relational databases such as MySQL, Oracle, SQL Server, PostgreSQL, and IBM DB2. Each sub connector within SQOOP knows how to connect and interact with a corresponding relational database for data export and import. It also serves a provision to connect to any database which is capable to use Java’s JDBC protocol. The connector also performs the optimization for MySQL and PostgreSQL databases which use database-specific APIs in order to perform bulk transfers efficiently.

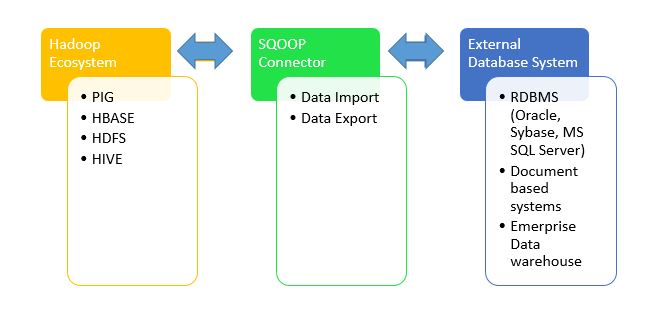
Apache SQOOP Architecture
In the above SQOOP architecture diagram, we have an SQOOP connector in between the Hadoop ecosystem (i.e. PIG, HBASE, HDFS, and Hive) and an external database system (i.e. enterprise data warehouses, relational databases (RDMS), MongoDB (NoSQL system)). The connector provides a database connection as well as a data transfer mechanism between the Hadoop ecosystem and an external database system.
Not only this, SQOOP supplies various third-party connectors for data stores which range from enterprise data warehouses (including Teradata, Netezza, and Oracle) to NoSQL stores (such as MongoDB, and Couchbase). Such additional connectors are not bundled with Sqoop by default, but those need to be downloaded separately in order to put them in use for the existing Sqoop installation.
Hadoop requires loading of bulk data from multiple heterogeneous data sources into Hadoop clusters for analytical processing which poses multiple challenges in terms of maintaining data consistency and efficient resource utilization. These are some of the factors which need to be considered before selecting the right approach for data load. Given below are some of the major issues.
- Scripts based data loading: It is a traditional approach to load data into databases but it is not suitable for the bulk data load into Hadoop. Such a script-based data loading approach is very inefficient and very time-consuming.
- Using Map-Reduce application for Direct access to external data: An alternate approach of direct access to load the data that reside at external systems (without loading into Hadoop) for map-reduce applications will simply complicate these applications and therefore, this approach is not practical.
- We can achieve the workability in order to work with the enormous data, by making the Hadoop system to work with the data in several altered forms and therefore, in order to load such heterogeneous data into Hadoop system, we require a different tool such as Flume which works with SQOOP to solve this problem. The features of the Flume tool has explained below.
Features of Flume
- A flume is a tool that is used for the bulk data streaming into HDFS.
- Flume is based on an agent-based architecture where the code is written (known as ‘agent’) that takes care of fetching of data.
- Flume enables the Data flows into the HDFS system via zero or more channels.
- Flume data load can be a data-driven event.
- Flume can be used to load streaming data such as tweets generated at Twitter, log files generated by a web server, etc.
- Flume agents are designed by keeping in mind the need to fetch the streaming data.
Conclusion
In this chapter, we discussed Apache SQOOP architecture and connector which serve as a medium to connect and perform the data transfer between the Hadoop ecosystem and the various external database sources.
>>> Checkout Big Data Tutorial List <<<
⇓ Subscribe Us ⇓
If you are not regular reader of this website then highly recommends you to Sign up for our free email newsletter!! Sign up just providing your email address below:
Happy Testing!!!